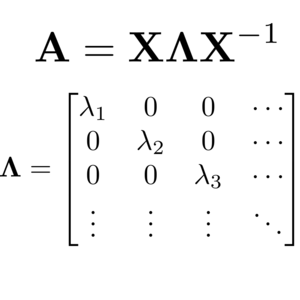Matrix diagonalization is a fundamental linear algebra operation with a wide range of applications in scientific and other fields of computing. At the same time, it is also one of the most expensive operations with a formal computational complexity of $\mathcal{O}(N^3)$, which can become a significant performance bottleneck as the size of the system grows. In this post, I will introduce the canonical algorithm for diagonalizing matrices in parallel computing to set the scene for today’s main topic: improving diagonalization performance. With the help of benchmark calculations, I will then demonstrate how a clever mathematical library choice can easily reduce the time needed to diagonalize a matrix by at least 50 %.